

实时数据大概可以算是数据开发人员所面临的最常见的伪需求。实时的Dashboard老实说并不会带来如想象中那么多的数据洞见,但其带来的心理感受足以安抚一大片非技术人员。看着当天的实时数字不断跳动,公司的投入毕竟没有白费。
于是工程师们一言不合地搭建起实时数据管道,一番工作后,一切就绪,打开浏览器,竟愕然发现,浏览器在不断地刷新!所以说,实时数据都是刷新出来的!公司有没有新的订单,完完全全取决于浏览器它刷新不刷新?!不刷新,我们就没有新订单,这也太反直觉了吧!于是兼职前端的Web开发终于放弃了上古时代的技术,用Ajax做了数据异步加载,刷新的过程用户变得无法感知。但仍然,这不是一个真正意义上的实时系统。
真正意义的实时系统,我们希望用户在下单这个动作发生时,更准确地说,通常是在支付成功时,后台的数据系统里可以及时看到今日订单数据的变化。所谓及时,就是说除去必不可少的系统损耗外,数据流向的整条链路上是不应该存在轮询动作的,整个流程都应该由支付这个事件驱动。不必说,轮询还意味着资源的浪费。
HTTP1.1及之前的协议,都建立在请求-响应模型之上,所有的通信需要客户端(也就是浏览器)主动发起。服务端即便感知到支付事件,也没有机制可以通过HTTP协议将消息推送到浏览器。而WebSocket协议实现了服务端和浏览器的双向通信,本篇博文将以Websocket为起点,从前端逐步往后地探讨如何打造整个基于事件驱动的实时数据系统。代码示例使用Tornado框架,可以在这个仓库中找到。

洪荒时代,Monolithic架构
作为一个minimum viable product,代码参见feature/v0.1_monolithic分支。简单设计了两个接口:
订单模块的ApiHandler用来处理第三方支付平台的支付成功回调信息。在整个请求-响应过程中,通过DB操作,更新订单信息。HTTP请求结束之后,查询当前的订单信息,将该消息发送到报表模块所有的WebSocket客户端:
class ApiHandler(web.RequestHandler):
"""订单模块支付宝支付成功回调接口"""
@web.asynchronous
def get(self, *args):
# 回调逻辑,数据库写入
order_id = int(self.get_argument("id"))
order_amount = int(self.get_argument("amount"))
new_order_flag = False
if session.query(Order.id).filter_by(id=order_id).scalar():
# 支付成功重复回调的情况,严谨起见还应该处理回调信息不一致的情况
print("重复回调")
pass
else:
# 增加订单记录;现实世界中,这里通常是改变订单的状态
session.add(Order(id=order_id, amount=order_amount))
session.commit()
new_order_flag = True
self.finish()
# 请求完成后,异步通过ws发送消息到客户端
if new_order_flag:
data = {"cnt": session.query(Order).count(), "amount": session.query(func.sum(Order.amount)).scalar()}
data = json.dumps(data)
for c in rpt_ws_cl:
c.write_message(data)报表模块的SocketHandler接受浏览器发出的WebSocket连接请求,将发起连接的用户加入到rpt_ws_cl变量中,并查询订单模块的数据库获取当前数据作为初始值,发送给客户端。
class SocketHandler(websocket.WebSocketHandler):
"""报表模块websocket连接"""
def check_origin(self, origin):
return True
def open(self):
# 查询今日订单
if self not in rpt_ws_cl:
rpt_ws_cl.append(self)
self.write_message(json.dumps({"cnt": session.query(Order).count(),
"amount": session.query(func.sum(Order.amount)).scalar()}))
def on_close(self):
if self in rpt_ws_cl:
rpt_ws_cl.remove(self)这个阶段的架构图如下所示:
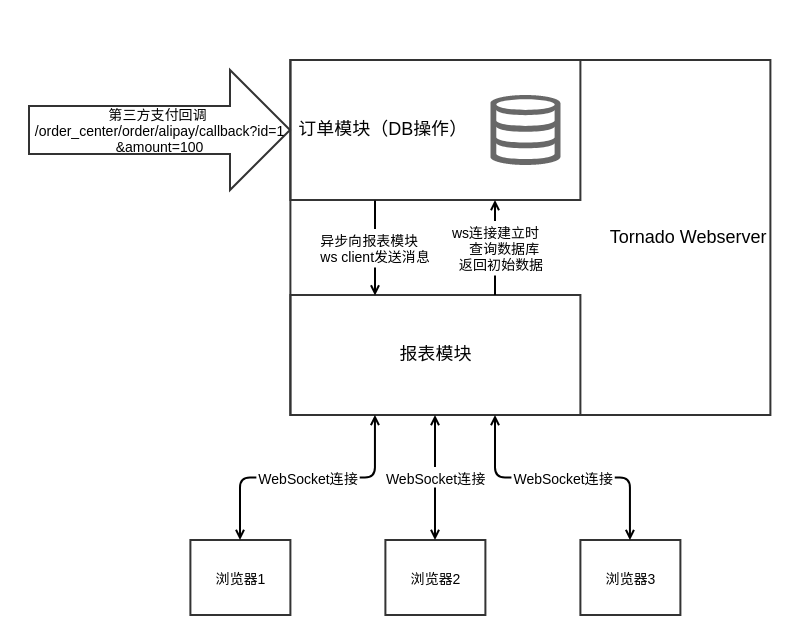
这里尽管我们区分了报表模块和订单模块,但实际上他们属于同一个Tornado应用。并且,模块之间的边界也很模糊。订单模块在收到支付回调请求,完成自身逻辑后,直接访问了报表模块的Websocket客户端列表。而报表模块在收到客户端连接请求时,为了获取初始数据,也直接访问了订单模块的数据库。它们本不应该这样通信。在这样的交互逻辑下,我们认为所谓报表模块只是订单模块所提供的一个管理后台也无不可。
但事实不是这样,可以想见,当业务量扩大之后,报表模块会需要来自更多模块的数据,比如网站的PV/UV,这是订单模块所不能提供的。订单和报表从逻辑上说就不是一体。
模块切分的另一个用意在于,当业务发展到某个阶段,流量爆发式增长,在已经做了读写分离方案的前提下,连写的数据库实例都达到了瓶颈,这时我们可以非常容易地对各个模块进行单独发布,打散单个模块的请求和数据库访问压力。
服务拆分成最小不可分单元,还遇到写瓶颈,就要考虑对数据库进行水平分片,也就是Sharding的概念,俗称分库分表。恭喜你,业务量级来到这一步的话,你们的产品想必离成功不远了。但这是后话。暂时不必想这么远,时刻谨记,过早的优化是万恶之源。我们暂且只考虑垂直拆分。
拆,必须要拆!
决定要拆分模块后,首先要考虑的问题是,拆分后的模块之间如何通信?一个显而易见的答案是,通过API通信。HTTP也好,Thrift也好,总有一款适合你。为了保证实时系统通过事件驱动,我们不能让报表模块去轮询订单模块的接口,而应该反过来,在订单模块完成订单支付回调逻辑后,异步调用报表模块的接口发送通知。
咋一看似乎很完美。可是……对,总有可是。想象我们不止一个模块需要下单动作的通知,比如业务监控系统想根据每小时的支付订单数来做环比告警,推荐系统想根据下单信息做实时推荐。嗯,几个模块要数据也不坏,都来订单模块注册一下,我挨个给你们发通知。随着模块增多,整个系统里终于出现了N个模块,相互调用API发送N2级别的消息通知。灾难性的架构。
更不必说,如果某个下游模块的API存在无法建立连接或接口调用失败的情况,订单模块是不是居然还要做失败重试?订单模块也很委屈,这也不是我份内的逻辑。通知发送成功不成功,毕竟并不影响到订单本身的处理。
对!既然是通知,显然,我们需要一个消息队列。订单模块只要往特定的队列里发送通知,任务完成。关心这条消息的模块,各自去订阅这个队列,收到消息后自行完成本身的处理逻辑,责任划分变得更加清晰。
比较成熟的消息队列,包括Kafka, RabbitMQ等,这里为了简便起见,我们以更为轻量的Redis Pub/Sub功能来做功能实现,代码可以参见feature/v0.2_pubsub分支。
修改后的订单模块回调接口如下,请求结束后,不再去访问报表模块的WebSocket客户端列表,而是将消息直接发送到Redis:
class ApiHandler(web.RequestHandler):
"""订单中心支付宝支付成功回调接口"""
redis_cli = redis.StrictRedis.from_url(REDIS_URI)
@web.asynchronous
def get(self, *args):
# 回调逻辑,数据库写入
order_id = int(self.get_argument("id"))
order_amount = int(self.get_argument("amount"))
new_order_flag = False
if session.query(Order.id).filter_by(id=order_id).scalar():
# 支付成功重复回调的情况,严谨起见还应该处理回调信息不一致的情况
print("重复回调")
pass
else:
# 增加订单记录;现实世界中,这里通常是改变订单的状态
session.add(Order(id=order_id, amount=order_amount))
session.commit()
new_order_flag = True
self.finish()
# 请求完成后,异步通过ws发送消息到客户端
if new_order_flag:
# 这里更常见的做法是,只发送增量数据,由消息订阅方自行聚合
data = {"cnt": session.query(Order).count(), "amount": session.query(func.sum(Order.amount)).scalar()}
self.redis_cli.publish(ORDER_CHANNEL, json.dumps(data))报表模块的SocketHandler,则将WebSocket客户端列表变为自己的私有变量(我知道,在Python里没有真正的私有变量,两个下划线也不行,但你明白这个意思的,对吧),不和外部共享。redis_listener方法,最终以一个单独的线程启动。Websocket连接建立时,也不再需要查询订单模块的数据库,而是本地保存了最新的消息状态。
class SocketHandler(websocket.WebSocketHandler):
"""报表系统websocket连接"""
redis_cli = redis.StrictRedis.from_url(REDIS_URI)
# 报表系统所有链接ws的客户端
_rpt_ws_cl = []
_latest_msg = json.dumps({"cnt": 0, "amount": 0})
def check_origin(self, origin):
return True
def open(self):
if self not in self._rpt_ws_cl:
self._rpt_ws_cl.append(self)
self.write_message(self._latest_msg)
def on_close(self):
if self in self._rpt_ws_cl:
self._rpt_ws_cl.remove(self)
# 报表系统订阅Redis信息
@classmethod
def redis_listener(cls):
ps = cls.redis_cli.pubsub()
ps.subscribe(ORDER_CHANNEL)
for msg in ps.listen():
if msg["type"] == "message":
cls._latest_msg = msg["data"]
for c in cls._rpt_ws_cl:
c.write_message(msg["data"])这个阶段的架构图如下所示:
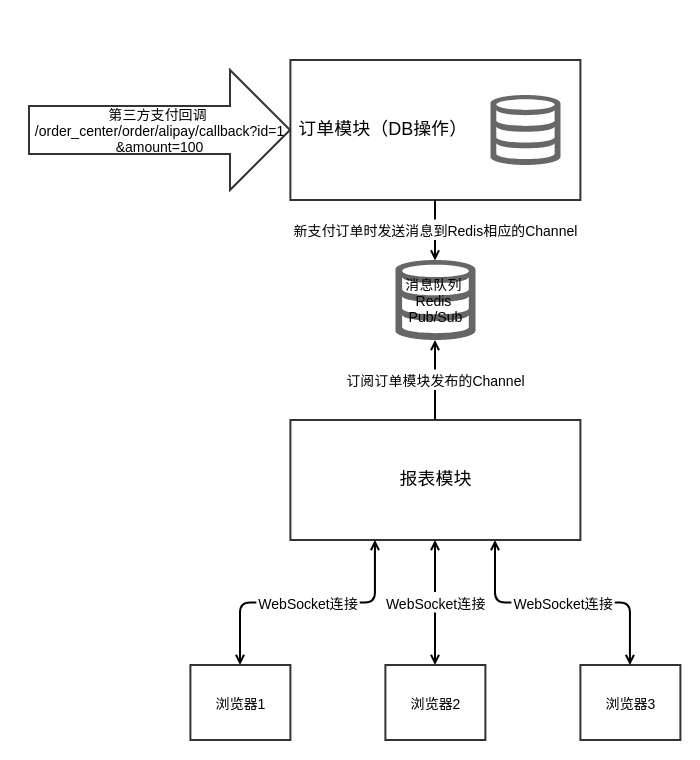
尽管在我们的示例代码中,两个模块的代码写在一个tornado实例中。但由于它们通过消息队列进行了解耦,相互不共享其它内容,他们是可以做到单独发布的。并且想象中作为消息订阅方的业务监控系统、推荐系统,也都可以非常容易地加入到这个架构中来。
消息队列在这里,就是事件驱动架构中常常提到的事件总线 Event Bus或消息总线 Message Bus的核心内容。
但故事到这里并没有结束,可能你已经发现了,我们的架构里仍然有不合理的地方,订单模块发送的消息,是查询数据库聚合好的全量结果。可是,想象中的业务监控系统、推荐系统显然会有不同的聚合或者更为复杂的数据处理方式,作为生产者的订单模块是不可能一一为其定制化处理的。并且查询全量数据对订单模块来说本身也是一种负担,它不应该做任何聚合,而是应当增量地发送当前订单的信息,由消费者自行聚合数据。
增量消息
当消息生产方开始发送增量数据,消费方的实时计算就成为了一个问题。消息量开始变大,这要求队列有更强的吞吐能力,消费者的速度也需要跟上,多线程消费是必然的选择,可能处理故障切换上需要稍稍花一点心思,花些时间也总能搞定。但也许有一天,单机的性能达到了瓶颈,走向分布式的消费,这个时候就必须要上实时计算框架了。
以保证巨大的消息吞吐量和复杂的实时计算为前提,通常这个技术栈就变成了以Kafka为消息队列,Spark Streaming或Storm进行分布式实时计算。实时聚合好的数据,再通过Redis Pub/Sub,或其他方案推送到数据库。
另外,对于增量消息本身来说,其实不限于系统本身发送的消息。你完全可以通过订阅数据库日志,比如MySQL的binlog来达到同样的目的,不过这样需要处理数据库表结构变更时日志格式变更的问题。为了将来实时数据管道的演进(参见下一节),这里不推荐使用数据库日志作为消息源。
由于涉及到的基础组件较多,就不在实例代码中进行演示了,不过相应修改过的代码注释,可以参见feature/v0.3_real-time_computing这个分支。这个时候,我们的架构变成了以下:
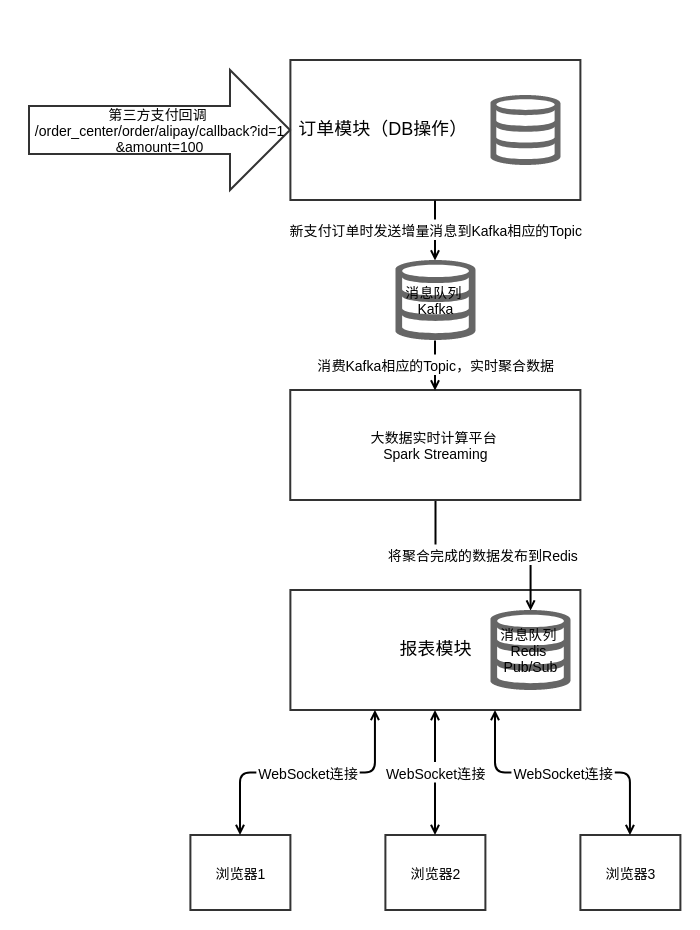
之前设想的业务监控系统、推荐系统,可以分别提交各自的实时计算作业到实时计算平台,消费同一队列。对于某些不需要实时计算的模块,比如有一个短信模块,需要在支付成功后给用户发确认短信,它还是可以直接订阅Kafka消息队列(通常不会是同一个Topic)。
至此,关于消息消费方的改造,我们可以说是取得了非常满意的进展。不过……你一定已经听出了言外之意,来到这个节点,我们对消息生产方有了更高的要求。
作为一个数据挖掘人员,我们总是拼命地拼命地想对用户的了解再多那么一点点。想要更多的了解,当然需要更多的数据。比如今天我想知道当天登录我们应用的用户数量,这个数据可能来自用户模块。明天我想知道,用户访问我们的商城进行了商品搜索,今天热搜的词是哪些,最常被搜索到的商品又是哪几款,这个数据可能来自商品模块。所以每当有一个需求,我就需要找到对应的业务系统,请求他们把数据发送一份到消息队列。
作为业务系统的开发人员,这个事件数据的需求做不做,其实一点也不影响我的系统功能,没有它业务也是正常运转的。而且很多数据发布出来,很可能只是为你一个数据系统服务。发布的消息多了,重构时代码里这些消息发送的逻辑,我也不知道还要不要维护。
两难!怎么办,这个时候我们可能需要一个统一的用户行为事件管理收集模块。在不侵入业务系统代码的情况下,把用户事件数据发布出来。
网关
我们都用过Nginx,作为反向代理,Nginx负责将客户端的HTTP请求,转发到对应的业务系统。Nginx的访问日志类似以下结构:
127.0.0.1 - - [26/Apr/2017:15:20:05 +0800] "GET / HTTP/1.1" 200 396 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36"它记录了访问客户端的IP,访问事件,请求方法,请求路径等信息。很大一部分用户行为,都会伴随着客户端向服务端发送HTTP请求。也就是说,这些行为,在发起到结束期间内的某个时刻,都会被Nginx忠实地记录下来。这让我们开始思考,我们能不能做一个模块,或者说我们能否改造Nginx,让所有的流量都流经我们这个中心模块,在这个模块之上,我们可以获得更多的业务信息,比如这个用户究竟是谁,而不仅仅是一个IP;用户请求的路径,到底对应着什么行为;面对用户的请求,对应的模块返回了什么样的数据给用户?
对,这就是API网关。业界比较知名的开源网关项目包括在Nginx之上基于Lua开发的Kong,Netflix开源基于Java开发的Zuul。网关作为流量的统一入口,可以做的事非常多,包括用户认证、安全监控、流量控制、缓存、日志记录、请求响应改造等等。对于数据人员来说,你只需要知道,它可以截获所有基于HTTP请求的用户行为,这就够了。
代码里使用BaseHandler来模拟网关,所有的HTTP请求Handler只要继承BaseHandler,就会在响应结束后,将相应的请求-响应数据发布到Kafka。代码参见feature/v0.4_api_gateway分支。最终的架构如图所示:
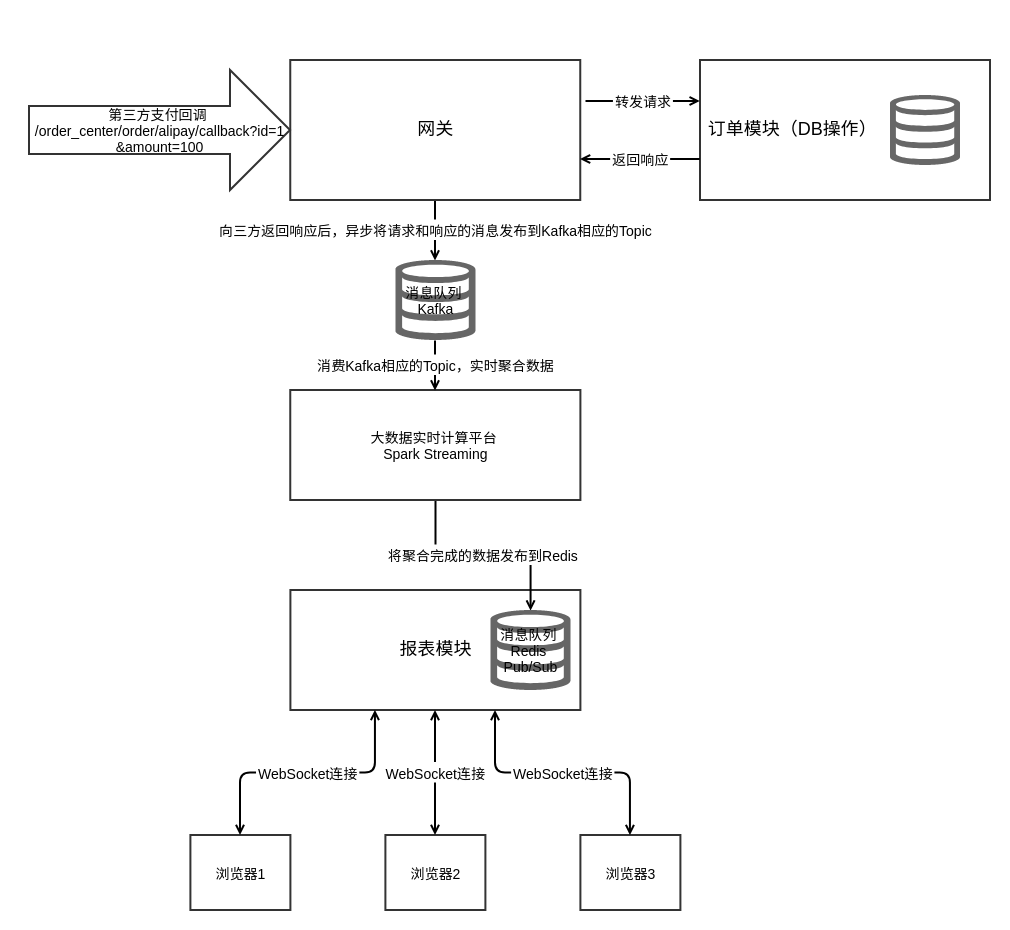
至此,我们将大数据实时系统和业务系统做了最大努力的解耦。业务系统在这里的意思是,没了它,公司的产品就立刻陷入瘫痪的系统,比如不能下单,比如无法查看商品列表。而我们的数据模块,说到底属于一个决策支持系统。如果你们公司有非常厉害的决策层,根据自己的商业直觉(传说中的Business Sense)或者一线调研,总能做出正确的商业判断,这套系统就可有可无。但通常来说,你很难碰上这么厉害的人,这种时候,相信数据会让你对自己的判断多一点点自信。(当然有时候你的论点也不必这么有数据支持,吵架嘛,最讲究的是气势)
对,这是最终了。Hooray!
最后的反思
回到原点,我在反思,我们真的那么需要实时数据吗。演变到最后的这个系统,对于绝大多数永远成为不了巨头的公司来说,是不是已经成为了屠龙之技?可能Monolithic时代的实时架构,结合T+1的数据挖掘分析,很多情况下就已经足够了。符合业务场景的架构,才是好的架构。
但不管怎样,只是从技术的角度来看,这一路走来,很有趣,对吗?不有趣,为什么要写代码呢?